Door Pieter Vogelaar 15 Februari 2026

In de wereld van Kubernetes zijn “requests” en “limits” de belangrijkste knoppen waaraan we draaien om applicatiestabiliteit en clusterefficiëntie te waarborgen. Op papier lijkt het logisch: vertel het cluster wat je nodig hebt (requests) en geef aan waar de grens ligt (limits).
Echter, als je CPU en geheugen op dezelfde manier behandelt, loop je waarschijnlijk tegen een muur aan qua prestaties. Terwijl memory limits (geheugenlimieten) een harde grens vormen voor stabiliteit, veroorzaken CPU limits vaak kunstmatige bottlenecks die de latentie verslechteren en ontwikkelaars en engineers frustreren.
Requests versus limits
Voordat we dieper ingaan op het “waarom”, bekijken we eerst wat deze parameters daadwerkelijk doen tijdens de levenscyclus van een pod:
- Requests: Deze worden gebruikt door de kube-scheduler. Als een pod 1 CPU aanvraagt, zoekt de scheduler een node met ten minste 1 beschikbare CPU. Het is een garantie op resources.
- Limits: Deze worden gehandhaafd door de container runtime. Ze vormen een plafond dat de container niet mag overschrijden.
De geheugenstrategie: Gegarandeerde Quality of Service
Geheugen is een niet-comprimeerbare resource. Als een container zonder geheugen komt te zitten, kan hij niet simpelweg “vertragen” — hij crasht (OOMKill).
Voor productieomgevingen is de best practice om de memory requests gelijk te stellen aan de limits.
- Vermijd overprovisioning: Door ze op dezelfde waarde in te stellen, creëer je een gegarandeerde Quality of Service (QoS).
- Voorspelbaarheid: De scheduler weet precies hoeveel geheugen er “verdwenen” is van de capaciteit van de node.
- Stabiliteit: Als de app binnen zijn grenzen blijft, is de kans veel kleiner dat deze door de kubelet wordt verwijderd (evicted) tijdens perioden van hoge druk op de node.
De CPU-valkuil: Het throttling-probleem
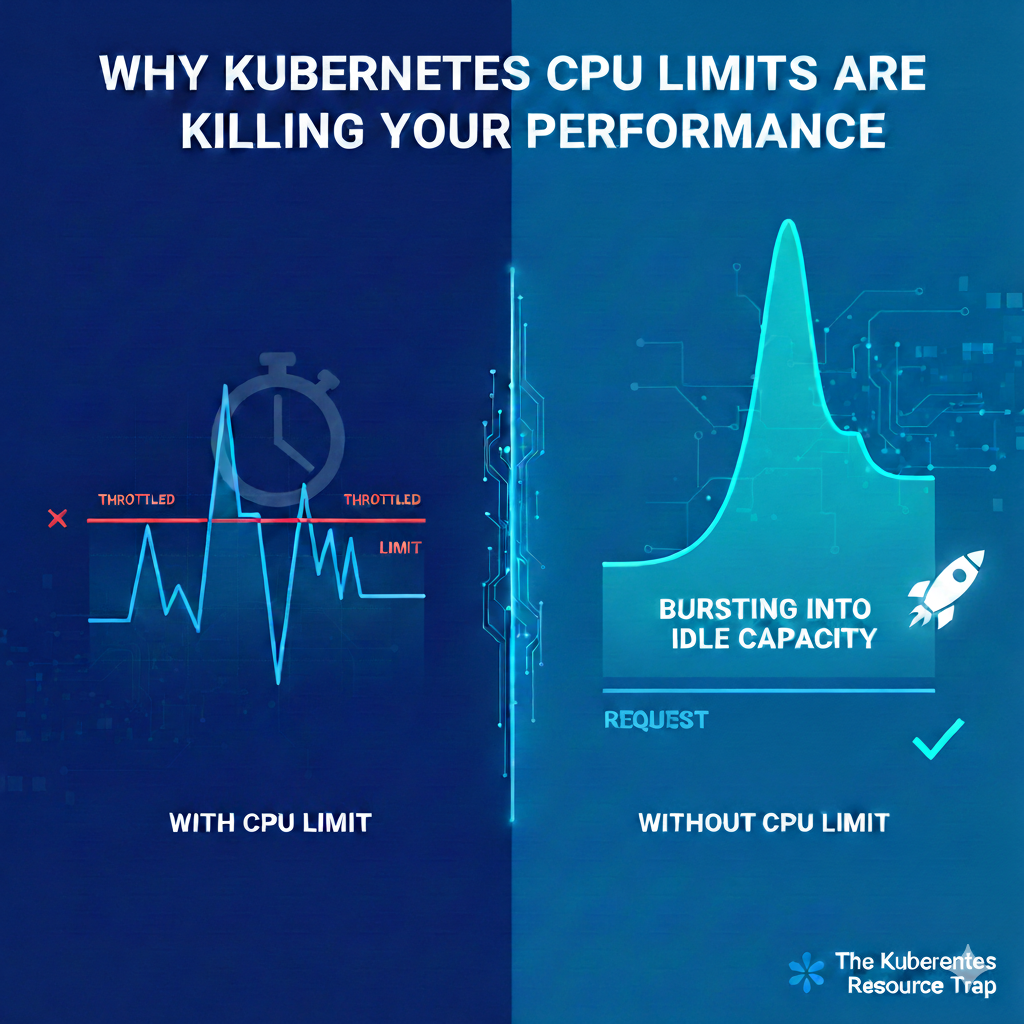
In tegenstelling tot geheugen is CPU een “comprimeerbare” resource. Als je de limiet bereikt, gaat het proces niet dood; het wordt afgeknepen (throttled).
Kubernetes handhaaft CPU-limieten met behulp van CFS (Completely Fair Scheduler) quota. Zelfs als de node 80% ongebruikte CPU-capaciteit heeft, zal de kernel je processen kunstmatig pauzeren tot de volgende handhavingsperiode zodra je container de gedefinieerde limiet raakt.
Het resultaat: De tail-latency (P99) van je applicatie schiet omhoog. P99 (het 99ste percentiel) vertegenwoordigt de langzaamste 1% van de verzoeken van je gebruikers. Een verzoek dat normaal 50ms duurt, kan plotseling 200ms duren omdat het CPU-“budget” voor dat milliseconde-venster op was.
Je applicatie draait misschien perfect bij P50 (de gemiddelde belasting). Echter, wanneer er een complex verzoek binnenkomt of er een kleine piek in het verkeer is, probeert de container “harder te werken”. Als de CPU-limiet wordt geraakt, pauzeert de Linux-kernel het proces gedurende enkele milliseconden. Voor de gebruiker voelt die pauze als een “hapering”. In je statistieken zie je dit terug als een enorme piek in P99-latentie, zelfs als je gemiddelde latentie er kerngezond uitziet.
Maar zelfs wanneer de applicatie ver onder de CPU-limiet zit, kan deze worden afgeknepen!
Dit gebeurt door de manier waarop de Linux-kernel deze limieten op milliseconde-niveau handhaaft. Het gaat niet alleen om de vraag of de “totale” limiet wordt bereikt, maar om de overhead en het micromanagement door de scheduler van de kernel.
Het handhavingsvenster van 100ms (CFS Quota)
De kernel kijkt niet naar je CPU-verbruik over een minuut of zelfs een seconde. Hij deelt de tijd doorgaans op in perioden van 100ms. Als je een limiet van 1 CPU hebt, mag je 100ms aan werk verrichten per periode van 100ms. Echter, als een applicatie multithreaded is (zoals de meeste moderne Go-, Java- of Node.js-apps), kunnen die threads dat budget van 100ms in een fractie van de tijd verbruiken.
Het scenario: Je hebt 10 threads. Elke thread doet 10ms aan werk direct aan het begin van het venster.
Het resultaat: Je hebt je budget van 100ms verbruikt in slechts 10ms. De kernel “throttelt” de container voor de resterende 90ms.
De beleving: Je monitoring zegt dat je 10% CPU hebt gebruikt (100ms van de mogelijke 1000ms over 10 cores), maar je app stond 90% van de tijd stil.
Waarom je zou moeten overwegen om CPU-limieten te verwijderen
- Moeilijk detecteerbare prestatievermindering: In tegenstelling tot geheugen-OOMKills, die luid en duidelijk in je logs staan, is CPU-throttling stil. Je app crasht niet; hij wordt alleen traag, wat prestatieproblemen ongelooflijk lastig maakt om op te lossen.
- Ongebruikte capaciteit: Waarom betalen voor een 16-core node als je app wordt afgeknepen op 1 core terwijl de andere 15 cores niets doen?
- Natuurlijk “bursten”: Zonder limiet kan je pod de reservekapaciteit van de node gebruiken (“bursten”) om een plotselinge verkeerspiek of een zware opstartfase op te vangen.
- Eenvoudiger schalen: Vertrouwen op CPU-requests zorgt ervoor dat je app heeft wat hij nodig heeft om te draaien, terwijl Horizontal Pod Autoscalers (HPA) het zware werk van horizontaal opschalen overnemen wanneer het cluster druk wordt.
Best practices voor resources
| Resource | Aanbevolen strategie | Waarom? |
|---|---|---|
| Geheugen | Request en limit | Garandeert de Quality of Service. |
| CPU | Alleen request | Voorkomt kunstmatige throttling en staat prestatiepieken toe. |
Voorbeeld
apiVersion: v1
kind: Pod
metadata:
name: optimized-app-pod
labels:
app: high-performance
spec:
containers:
- name: web-server
image: nginx:latest
resources:
requests:
# Zorgt dat de scheduler een node vindt met minstens 500m CPU
cpu: "500m"
# Request is gelijk aan limit voor geheugen (gegarandeerde QoS)
memory: "1Gi"
limits:
# Geen CPU-limiet: voorkomt CFS-throttling en staat bursting toe
# Geheugenlimiet wordt strikt gehandhaafd om OOM-problemen te voorkomen
memory: "1Gi"
Conclusie
Het instellen van CPU-limieten is vaak een defensieve configuratie, bedoeld om te voorkomen dat een proces op hol slaat en een hele node platlegt. Ze doen echter vaak meer kwaad dan goed. In moderne clusters wegen de resulterende prestatievermindering en latentiepieken veel zwaarder dan de veiligheidsvoordelen.
Begin met het instellen van verstandige requests op basis van je baseline-metingen, laat de CPU limit leeg en geef je applicaties de ruimte om te ademen.
Vogelaar Solutions helpt organisaties met DevOps, platform engineering en web development. Neem contact op voor een vrijblijvend gesprek.